Импортируем модуль pandas:
import pandas as pd
В основе работы pandas лежит табличное представление данных:

В качестве примера рассмотрим данные о пассажирах Титаника.
Для ряда пассажиров я знаю имя (символы), возраст (целые числа) и пол (мужской / женский).
df = pd.DataFrame({
"Name": ["Braund, Mr. Owen Harris",
"Allen, Mr. William Henry",
"Bonnell, Miss. Elizabeth"],
"Age": [22, 35, 58],
"Sex": ["male", "male", "female"]}
)
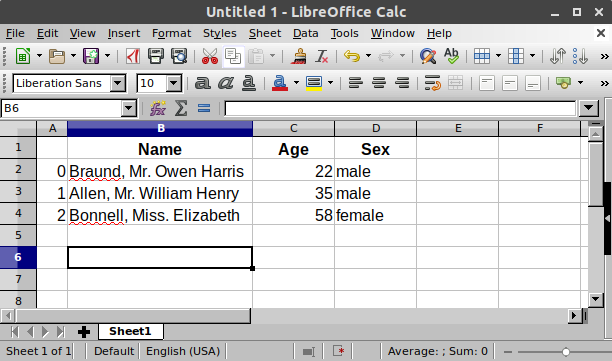
df
| Name | Age | Sex | |
|---|---|---|---|
| 0 | Braund, Mr. Owen Harris | 22 | male |
| 1 | Allen, Mr. William Henry | 35 | male |
| 2 | Bonnell, Miss. Elizabeth | 58 | female |
Полученная структура данных называется DataFrame.
Напоминает обычные таблицы:
Каждый столбец в структуре DataFrame является типом Series:

Выбрать столбец из таблицы:
df["Age"]
0 22 1 35 2 58 Name: Age, dtype: int64
Внешне очень напоминает питоновский словарь.
Вы также можете создать Series с нуля:
ages = pd.Series([22, 35, 58], name="Age")
ages
0 22 1 35 2 58 Name: Age, dtype: int64
Я хочу узнать максимальный возраст пассажиров, применив функцию max() к столбцу таблицы:
df["Age"].max()
58
или к типу данных Series:
ages.max()
58
Помимо поиска максимального в pandas существует большой набор функций.
Если интересует некоторая базовая статистика числовых данных:
df.describe()
| Age | |
|---|---|
| count | 3.000000 |
| mean | 38.333333 |
| std | 18.230012 |
| min | 22.000000 |
| 25% | 28.500000 |
| 50% | 35.000000 |
| 75% | 46.500000 |
| max | 58.000000 |
describe() метод обеспечивает краткий обзор численных данных в DataFrame.
Так как столбцы Name и Sex состоят из текстовых данных, то они не учитываются в describe().
Многие операции в pandas возвращают DataFrame или Series.
